

Editors Note: This is the first in a series of blogs aimed at development teams and coaches interested in finding the right practices to use for the development challenges that they face.
Every development endeavor is different
Some are more different than others. Let’s take a couple of extreme examples.
If what you are building is a smartphone app, then it’s often all about shiny, attractive features1, right?
So, a good place to start might be to brainstorm lots of possible “killer features”. Then agree which you want to build into a first Minimum Viable Product (MVP)2. Then chop these up into smaller “Product Backlog Items” or “User Stories”, so that you can build, test and demonstrate many of these each development heartbeat or Sprint (if you are using Scrum or a Scrum-like approach) or deliver new “work items” frequently (if you are using Kanban or similar lean “continuous flow” approach).
But what if you are automating a complex business process, or building a new digital service, such as (to take a few examples from the author’s development project experiences):
- Online loan applications – from initial application to loan offer
- Trade Processing – from initial trade to account postings completed
- Organ transplant – from donor-recipient matching to organ transplant procedure
- National statistics calculation – such as headline inflation or unemployment figures.
Here “shiny features” are not of primary importance. Sure, if you ask users to brainstorm what features they want, they will tell you. But if you start to build the solution one such feature at a time, the chances are you won’t have a system that is usable in a live environment for a very long time. Which, as an approach to maximizing value/return-on-investment, basically stinks.
With these kinds of systems we need to take a different approach to being value-driven and to delivering new value early-and-often.
Focusing on Value
A useful guiding mantra with these kinds of systems is “if some users can achieve an end-goal, then we have built something of at least some value that we could potentially release”.
So, with this kind of system in particular, a great first question to ask is not “what features could we build”, but rather “what kind of people will use this” and “what will they use it for”.
| Answers to the second question are known as “use cases” and answers to the first question are known as “actors”. Both answers can be neatly captured in a “big visible information radiator” as a use-case diagram, for example as shown to the right: |
 Figure 1: A Use Case enables a user type (Actor) to achieve a goal (and therefore get value)
Figure 1: A Use Case enables a user type (Actor) to achieve a goal (and therefore get value) |
Even for large systems, there are often relatively few of these use cases – maybe up to a dozen or so. Of these, sometimes there are as few as one or two use cases that we will want to focus on initially for a first product release, such as the “Apply for Student Loan” use case shown above.
This is both the good news (relatively few use cases) and the bad news (a single use case can represent a significant percentage of the total system build time/cost).
So, in order to be able to deliver value early-and-often, the next step is to start cutting these big use cases into smaller parts.
Use-Case Steps
There are two different directions in which we can start to “cut” – horizontal or vertical3.
An obvious way to cut such a use case is vertically into “steps”, for example as shown below4:
 Figure 2: Identifying smaller “steps to value” within a Use Case
Figure 2: Identifying smaller “steps to value” within a Use Case
These steps are useful things to recognize for the development team. For example, we can design screens for each step, prototype them, and even test these screen prototypes with end-users.
But if we were to incrementally build and test the system one of these steps at a time, the BIG problem is we won’t have anything that enables any users to achieve their goal until we have built all the steps, which is often pretty much the whole system. Which, as we have already said, is the worst possible way to maximize value/return-on-investment.
Finding Slices of Releasable Value
The key to finding releasable subsets of the whole system is to split the use case in the opposite direction – by identifying “end-to-end”, “horizontal” use-case “slices”, each of which achieves at least some end-users’ end-goals, and therefore realizes at least some genuine end-user value.
Often with complicated business processes there are a huge number of possible paths through the system. An easy way to define releasable increments is to constrain the set of paths that each release will support. For example, a first release of a Process Trade use case might be designed and built to support only the cases where Trade Instrument = Shares; Trade Location = UK; Account Location = UK; Exchange = UK Stock Exchange; Trade Currency = UK Sterling5.
And to figure out the best order to “build and release” our slices, we can use a simple, standard economic model, informally known as “bang-for-buck” (and more formally known as “Weighted Shortest Job First” or “Cost-of-Delay-divided-by-duration”)6. For example, if the above trade processing “slice” is roughly 80% of our business by value, and only roughly 20% of the complexity of the whole system, then this might be a good thing to build and release first.
If we return to the student loan example, the result of slicing the use-case in this way might look as shown below7:
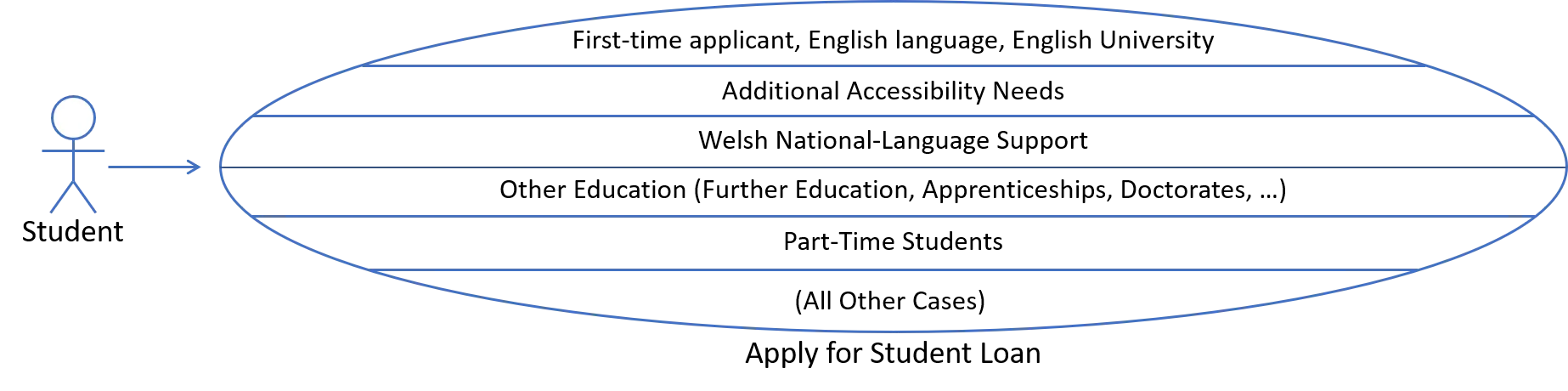 Figure 3: Use Case Slices are end-to-end paths through a Use Case taken by a subset of cases
Figure 3: Use Case Slices are end-to-end paths through a Use Case taken by a subset of cases
The IJI Use Case 2.0 Practice includes guidance and techniques for progressively splitting thinner and thinner slices as required to support a value-driven, lean/agile delivery approach at every level, for example:
- To initially identify top-level slices that represent candidate releases
- To slice thinner as needed to find candidate Product Backlog Items
- If a candidate Product Backlog Item is too big (e.g. to fit into a Sprint), to slice even thinner as and when needed – potentially as thin as a single end-to-end test case if needed.
Using Use Cases in Combination with other Practices
As we will see in later blogs, this approach to slicing thinner and thinner slices of end-user value is a powerful practice that can be used in combination with any number of agile management practices and frameworks, including Scrum, Kanban and SAFe®.
The only challenge is that these different management practices use different names for “small things that we progressively build into the product to increase its value”, for example:
- In Scrum, these are called “Product Backlog Items”
- In Kanban they are called “Work Items”
- In SAFe they are called different things at different levels - Stories, Features, Capabilities etc.
The bottom line is that Use-Case Slices make great Product Backlog Items / Work Items / Features / Stories etc. because:
- They are by definition independently valuable8
- They can be sliced and sliced again on an as-needs, just-enough, just-in-time basis to make them small enough to be flowed efficiently through a development process (including down through different levels of backlog in a multi-level scaled agile model).
Use Cases or Features?
Returning to our original question, we can now see clearly that it is the wrong question to ask!
We should not be thinking “features or use cases”, but rather about what is the best way to:
- Identify and prioritize small increments of releasable value (candidate releases)
- Split these (if and when needed) into smaller items that we can independently prioritize, schedule, build, test and demonstrate (product backlog items).
Use-case slices are a simple but powerful technique for doing exactly this.
They are especially invaluable when the solution we are building is the automation of a business process, such as an e-commerce, digital service, or “straight-through processing” system. But even here we might use a combination of use cases with other approaches to identify the different kinds of value we could build into the product, e.g. “features” that add extra value to many use-case slices, such as a “Loan status text alerts” feature for example.
And it matters not at all what we choose to call the results of the use-case slicing process – they might become candidate MVPs, MMPs, Features, Product Backlog Items, User Stories, Work Items or whatever our chosen work management practices choose to call these value increments and items.

-
“Feature” is a popular concept with a long and varied history (including as part of the Rational Unified Process (RUP) , Feature-Driven Development (FDD), Scaled Agile Framework (SAFe) etc.) and, unfortunately, is defined and applied differently each time (http://www.jot.fm/issues/issue_2009_07/column5/ for example lists 10 different definitions). In general, and loosely speaking, a feature tends to be anything of significant, independent value – the kind of thing that might be listed “on the back of the box” (or in the brief description of an app in an app store), and this is the general sense in which I use it here. Note that SAFe Features have a very specific meaning and play a very specific role in that framework (see https://www.scaledagileframework.com/features-and-capabilities). I intend to look specifically at SAFe Features in a separate blog on using use cases with SAFe. ↩︎
-
I use this term in its “original” meaning, as introduced by Eric Ries in “The Lean Startup”, and further elaborated by him in “the Startup Way” – i.e. as a “limited liability experiment” to learn by testing a hypothesis, NOT a fully engineered, generally releasable product. The latter I shall refer to as a Minimum Marketable Product (MMP) ↩︎
-
While the “horizontal” versus “vertical” distinction is common in software development, unfortunately it varies as to which means what, depending on which way around you happen to draw your diagrams! I stick throughout to the most natural orientation when using Use Cases, which is that “horizontal” is an “end-to-end” interaction that culminates in the achieving of the end-goal of the use case, whereas “vertical” is a non-releasable chunk of software, either comprising a solution implementation layer (e.g. “just the user interface”) or just one step towards value (e.g. “just the initial user registration step”). ↩︎
-
Here we are showing the “normal flow” case (sometimes called the “basic flow”) – the typical way the loan process flows “end-to-end” – there are clearly many possible “alternative” or “exception” paths, but for the sake of brevity we will not consider these here. ↩︎
-
Which was roughly what happened with the new trade-processing system that this example is loosely based on. In the first release of the new system all other trade types were simply intercepted “at the front gate” and channelled through the existing system. ↩︎
-
See for example Donald Reinertsen’s “The Principles of Product Development Flow”. ↩︎
-
Also loosely based on a real example. ↩︎
-
I deliberately use and emphasize key elements of Bill Wake’s most excellent INVEST mnemonic https://en.wikipedia.org/wiki/INVEST_(mnemonic). ↩︎